
Github https://github.com/TanStack/query 33k star
0x00 首先,为什么我们需要React Query
顾名思义,React Query 是一个请求库,但是这个命名并不准确,因为这个请求库本身并不处理请求 —— 他本身不会以任何方式向外发起任何请求。相比请求库,他更像是一个请求缓存层。
一个简单的使用大概是这样的:
1 | function Example() { |
相比于一般的在组件中发起请求,React Query通过 useQuery 帮我们自然而然的生成了一个请求中间层。
原始:

使用React Query后:

而从单个请求来看的话,似乎增加了这一层以后没有任何的收益
那么我们拓展一下呢?
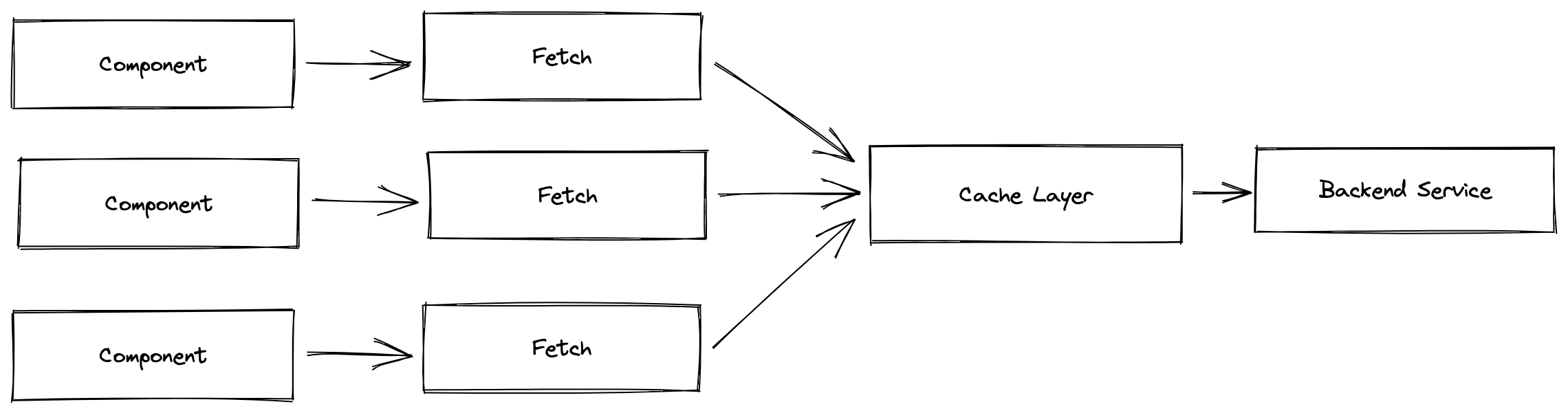
可以看到,通过一个中间的缓存层,我们可以把相同的组件同时发出的多个同样的请求合并成一个发送给服务端,这样对于服务端来说请求压力会减少很多。
但是,我们完全可以把相同的请求放在同一个地方,然后把结果传递给使用的组件,那么是不是就完全不需要面对这种情况了呢?
是的,我们在大部分时间做的就是这样的方式,很少会出现相同的请求发送很多遍的情况。但是这也是我要说的React Query通过中间层带给我们的最大的意义 —— 解耦。
想象一下,我们有以下这样的组件:
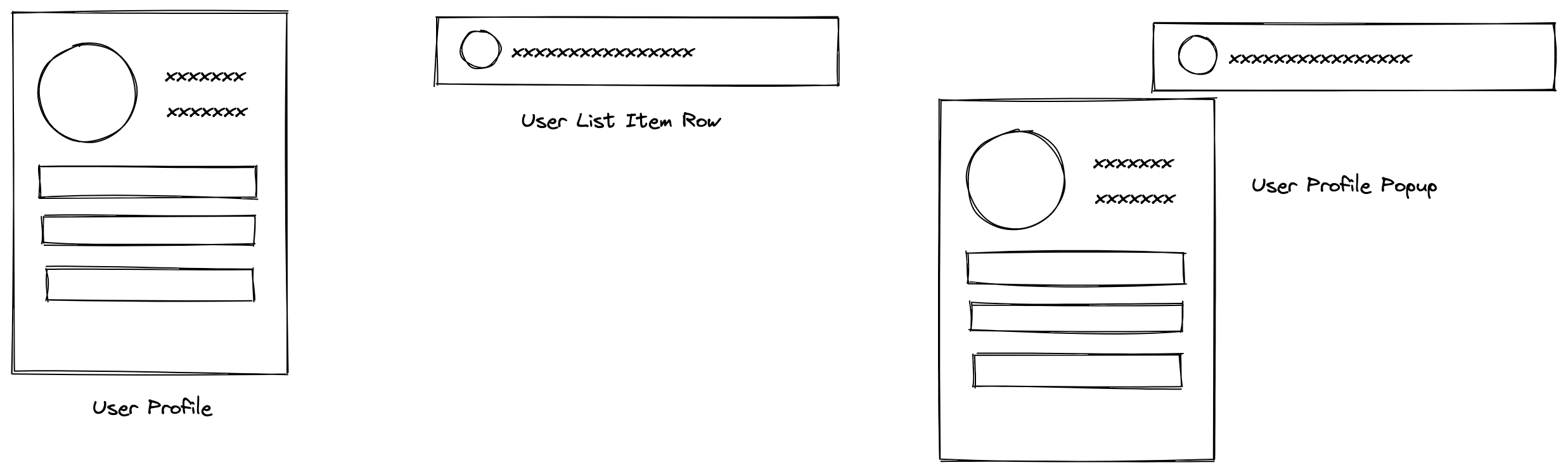
分别代表了用户信息组件,用户简单信息列表项,以及他们组合的产物。他们都需要获取最新的用户信息,用的是同样的接口。我们分别叫他们组件A,组件B和组件C吧。
当我们单独处理组件A和组件B时,我们只需要在组件挂载阶段去获取远程的数据即可。这非常容易,但如何我们将他们组件使用以后,一些问题就会出现了:我们不可能让他发起两次同样的请求,按照我们之前的做法,我们就需要在组件B渲染的阶段把数据拿到,然后在组件A弹出的时候将组件B获取到的数据传递进去。
这很容易,但是这也带来了上下文。即组件A既有自己获取数据的逻辑,又有根据上下文获取数据的逻辑。这种方式的数据管理是复杂的,难以维护的。
而通过React Query带来的缓存层,我们就无需关心请求的细节,每个组件都可以只关心自己的事情而无需关心上下文。所有的请求将会由一个统一的缓冲层来帮助我们统一管理请求数据。
0x01 数据活性
大家都知道,数据是有时效性的。在我们的HTTP协议中带来了一个新鲜度的概念,即在每次请求中标注一下一个请求的时效性,就类似食品的保质期一样。相比于缓存,我更加喜欢用数据活性这个概念,因为数据是有生命周期的。
在时效性有效的范围内,我们可以认为请求的资源是“新鲜的”,那么我们就可以在下次发送网络请求的时候不再向远程发送请求,而是使用本地记录的上一条结果。而如果请求的时间过了时效范围,那么这个请求将会被标记为“陈旧的”,那么再发起新的请求以后,就会真实的向服务器发送网络请求。这就是我们一般意义上的缓存。
而在service worker中, 有一种新的网络缓存管理概念,名为: Stale-while-revalidate
其意义上在于,在service worker代理网络请求的时候,为了确保用户每次都能非常快速的加载页面,sw会第一时间去从本地缓存中拿取数据返回给页面,但是同时在后台发送真实的网络请求去获取最新的内容并更新本地缓存。这样用户不会第一时间拿到最新的数据,而是以最快的速度打开页面,而在后台请求以确保下次的内容更新。
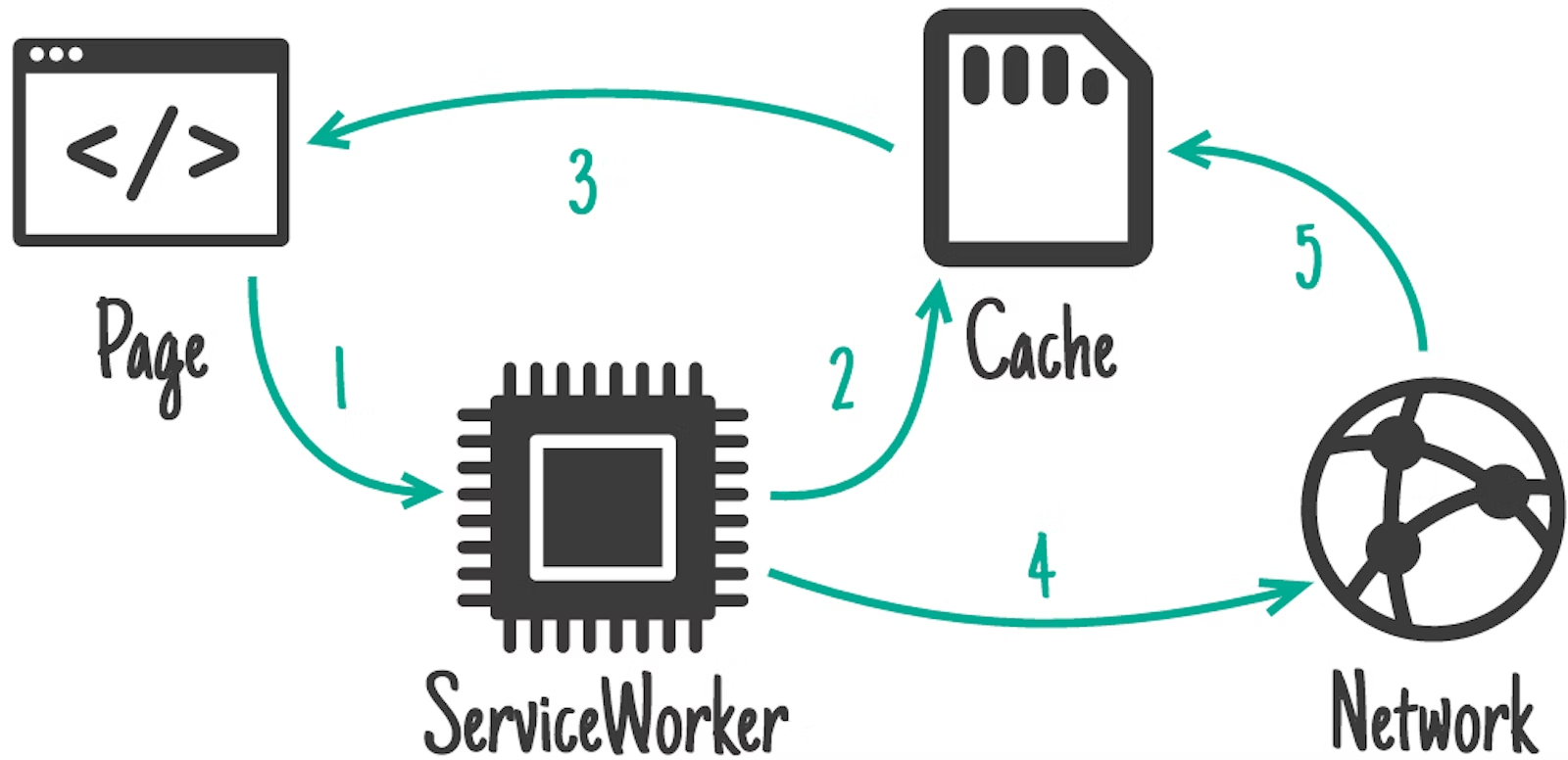
更多详细说明: https://developer.chrome.com/docs/workbox/caching-strategies-overview/#stale-while-revalidate
而React Query 在这方面做的更加好,相比于Promise的一次性的数据获取,hooks带来了允许主动发起的多次数据更新。这意味着React Query能做到更加复杂的数据更新策略。
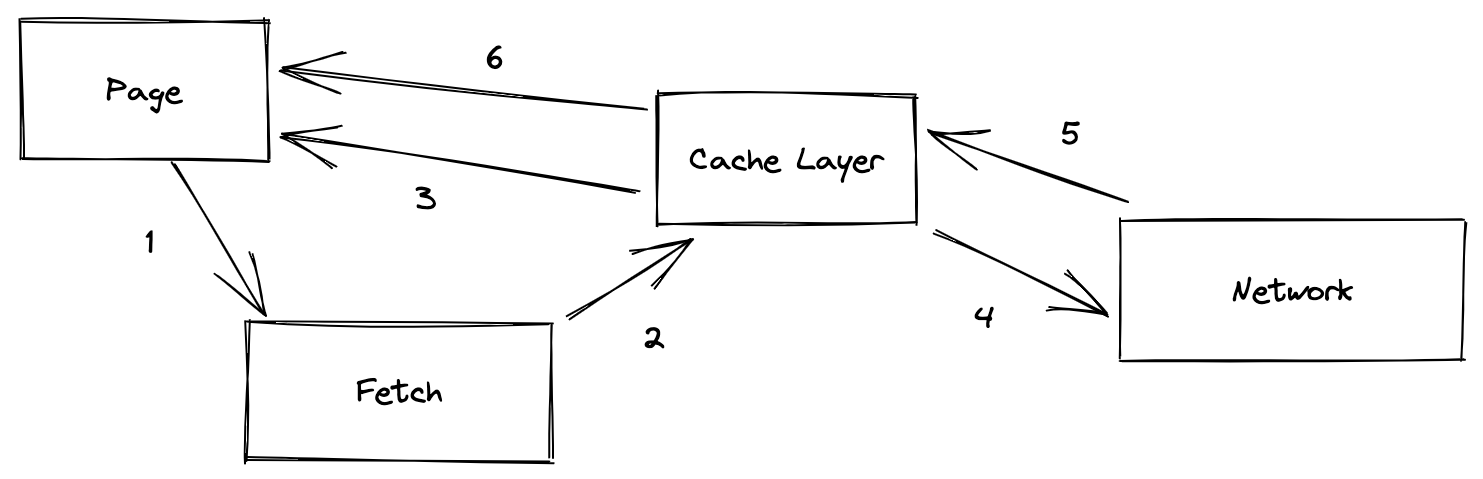
上图则是React Query在进行“陈旧”数据的处理方式,如果一条请求被标记为“陈旧”而不是“过期”,那么在 hooks 中,React Query会第一时间将旧的数据返回给前端,与此同时再向服务器发送网络请求,当网络请求的结果回来后,通过hooks 再一次更新数据。
对于标记的“陈旧”与“过期”的概念,就是在请求的时候定义的“slateTime” 与 “cacheTime”,区别就在于如果之前请求过,是否要第一时间返回到前端,然后二次更新最新的数据,还是选择直接等着网络的返回。可以看得出非常精确了。
同时,如果一个组件挂载后很长时间不更新,但是新的组件被更新数据以后,旧的组件也会同样更新保持数据一致性,用户在管理数据方面就没有任何压力了。
0x02 不仅仅是 react 与 query
坦白的讲,React Query的名字起的并不好。在我上面的讲述中大家可以发现,React Query做的其实并不是query的事情而是cache的事情,我们可以在其中管理任何的异步操作,比如一个高CPU的算法,比如一个与web worker的通讯结果。
另一方面,React Query 与 React 的关系在于他通过 react hooks 实现的数据响应式更新。然而其实什么方式并不重要,如果我们做一些抽象是不是能够作用到任何的数据驱动的框架中呢?事实上新版的React Query 也是这么做的。
可以看到在新的结构中,拆分了内核包与各种框架的适配层。
这就是为什么我说他的名字起的并不好,具有很强的误导性。react query,即跟react无关,又与query没有直接关系。只能说历史原因难以修改,这也是为什么我在平时的工作中一直强调尽可能的减少技术负债,因为有的技术负债一旦背上可能就永远摆脱不掉了。