概述
正确的查询方式与正确的索引可以极大增加数据的查询效率,能极大提升服务器响应时间。对于较大的并发服务来说一点点提升也有比较大的收益。
sql调优
一条sql语句的执行过程: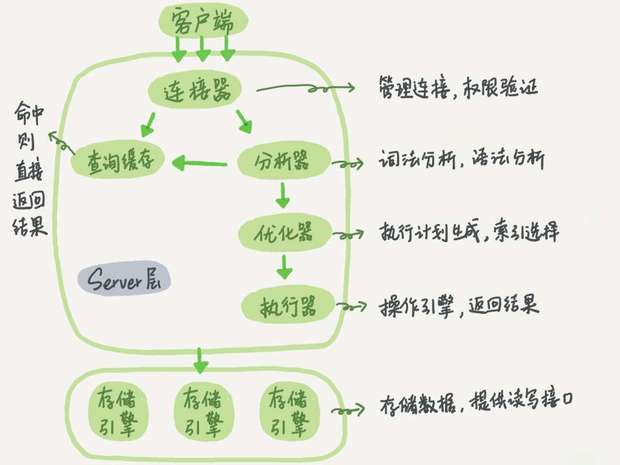
mysql分为server层和存储引擎层两个部分;
Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
而存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。
现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
使用show create table 语句查看一张表的DDL
show create table user
使用desc或explain调优sql语句
e.g. : desc select * from user
即在要执行的语句前可以加上desc或explain查看该语句的查询操作。(两者操作是等价的)
该命令会列出以下项:
- id
- select_type
- table
- partitions
- type
- possible_key
- key
- key_len
- ref
- rows
- filterd
- Extra
其中我们主要需要关心的有三列: key, rows 与 filtered
其中:
key主要是表示当前查询用到的键
rows表示查询后返回的行数
filtered表示当前查询过滤了多少。 100表示完全没有进行过滤,是最佳的情况。因为where操作是很消耗性能的
简单的,如select count(1) from employees where gender = 'M'
我们可以通过简单的增加一个索引来实现优化: alter table employees add index(gender)
select count(1) 表示仅返回数据量而不关心数据值 减少其他变量影响结果
这样当我们使用desc语句时可以看到key变为了gender, rows数量为返回的数量,filtered变为了100。可以注意到的是,Extra的值从Using where变为Using index。说明我们这条语句使用了索引
而对于多条件的查询。我们可以通过联合索引来进行优化
如以下查询:select count(1) from employees where gender = 'F' and birth_date > '1964-01-01'
则可以通过增加联合索引来进行优化alter table employees add key (gender, birth_date)
注意: 联合索引的顺序很重要,如果顺序不对则无法进行优化
如果我们想在select时统计别的数据,如以下查询:select count(distinct birth_date) from employees where gender = 'F'
我们也可以使用联合索引进行调优alter table employees add key (birth_date, gender)
同样的。需要注意顺序, 不过要注意比如是(birth_date, gender), 虽然都是filtered: 100但是执行效率仍有区别
区别如下:
(birth_date, gender):key_len为4, 即用到了两个键(gender是tiny,长度1,birth_date是日期,长度4)。rows为4788,Extra为Using where; Using index for group-by(gender, birth_date):key_len为1, 只用到了gender键。rows为149734,Extra为Using index
而对于一些无法优化的。如双向like操作,也可以通过联合索引来应用一部分索引增加部分速度(虽然只会应用一部分)
如select count(1) from employees where gender = 'F' and first_name like '%a%' and last_name like '%b%';
可以增加联合索引实现索引下推功能:alter table employees drop key gender, add key (gender, first_name, last_name);
优化总结
- 每个索引都是一个BTree(MySQL一般是B+Tree)
- 什么时候加索引:搜索条件固定,数据分布不均(即需要全表搜索)
- 双向like是没法优化的
- 联合索引受顺序影响。而且如果最左索引是范围的话无法使用后面的
- 使用索引下推,可以减少从主键树上取数据的时间
- 大多数复杂情况or查询是无法优化的, 但是一些简单查询可以优化
- 尽量使用join查询而不是子查询,因为join查询能被优化而子查询不行